(1) How does Scheduler Work?
The scheduler is one of the main functions of a real-time OS. How is it implemented in a real-time OS? Let’s see how a task execution order is controlled.
The OS chooses the next task to be executed according to specified rules. Creating a queue of tasks waiting for execution according to specified rules is called scheduling. The kernel, which is almost like the core of the OS, provides the scheduler functions, which handle the scheduling of tasks waiting for execution. The following describes commonly used task scheduling algorithms.
1. First Come, First Served (FCFS)
The task that enters the execution waiting state first is executed first. Waiting tasks are put in a queue in the order they enter the waiting state.
2. Priority Based
Each task is assigned a priority level, and tasks are executed in the order of priority.
The algorithm for switching tasks at specified intervals and repeatedly executing them in turn is called round-robin scheduling. There are other scheduling algorithms, such as the deadline-driven scheduling algorithm, which assigns CPU execution to the task nearest to its deadline, and the shortest processing time first (SPT) algorithm, which assigns CPU execution to the task that requires the shortest processing time when the necessary time for each task is known.
An embedded OS such as μITRON uses both priority-based and FCFS algorithms. The highest-priority task is executed first, and if multiple tasks have the same priority, they are executed in an FCFS manner. Tasks in the execution waiting queue (called the ready queue) can also be executed in a round-robin manner; that is, execution is cyclically switched among tasks at specified intervals.
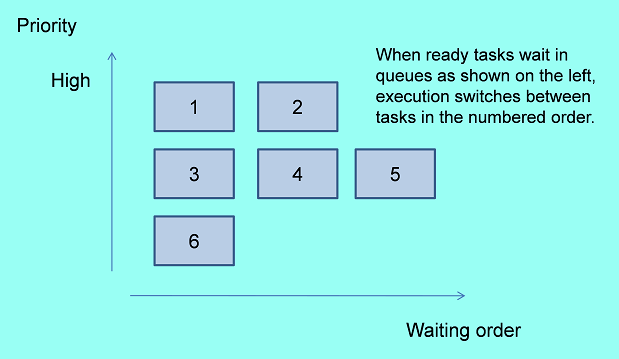
(2) When is Scheduler Activated?
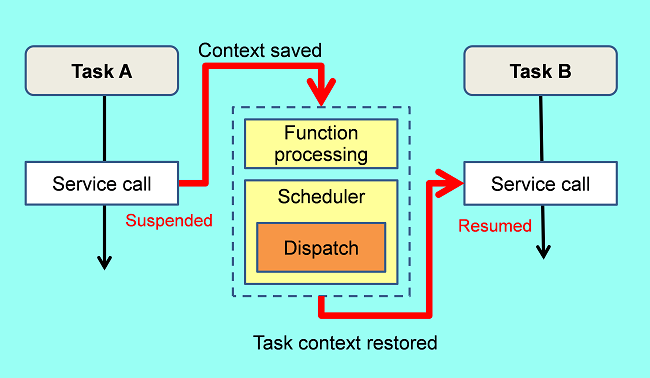
The scheduler is activated every time a task or a handler requests a service from the OS. This request to the OS is called a service call. When a service call is issued, control is shifted to the OS. After the OS has processed the requested service, the scheduler chooses the next task to be executed and switches execution to the task. Switching between tasks is called a task switch, and the act of switching is called dispatching. After dispatching, CPU execution is shifted to the chosen task. Necessary data is saved so that the previous task can continue execution when it is later dispatched. The data necessary for restarting execution is called a context.
The number of provided service calls depends on the functions of each OS. In C-language programs, service calls are issued through function calls. Target tasks or wait times are passed to the OS as arguments of functions.
[Service Call Examples]
- sta_tsk Activate a task
- ext_tsk Terminate the invoking task
- wup_tsk Wake up a task
(3) Difference between a Task and a Handler
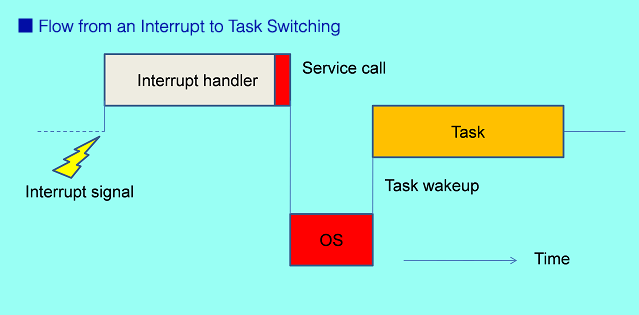
As described earlier, the target of scheduling and dispatching is a task. A task is activated, suspended, resumed, or terminated by the OS. An interrupt program, however, is automatically activated without OS intervention when a dedicated signal is input to the microprocessor; it is a program that is not controlled by the OS. When this program issues a service call, control is shifted to the OS and tasks can be processed through the OS. This type of program is used when tasks should be processed upon generation of an event notified through an interrupt. A program that issues service calls but is not a task is called a handler. A handler that is activated by an interrupt is called an interrupt handler. In addition to interrupt handlers, there are cyclic handlers, which are activated at specified intervals, and alarm handlers, which are activated at a specified time or after a specified period.
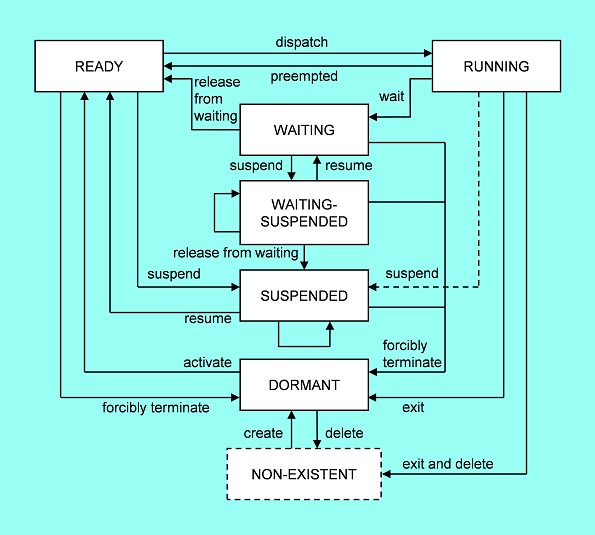
(4) Task State Transition
The scheduler described earlier determines which task in the execution-ready task queue should be executed. A task dynamically moves between various states; for example, a task being executed enters a waiting state or a waiting task enters an execution-ready state when the wait state is canceled upon generation of an event. The OS manages the state of each task. There are three basic task states as shown in the figure below. RUNNING state is the state of a task being executed, which is entered when a task in READY state is chosen (dispatched) to be executed. When a RUNNING task is suspended (preempted), it enters READY state. In a single CPU, only one task can be in RUNNING state. Scheduling is the act of determining which task in READY state should be shifted to RUNNING. μITRON can handle six main states including DORMANT state, WAITING-SUSPENDED state, and SUSPENDED state.
(5) Dividing Tasks
What should we consider when dividing tasks? Let’s look at some cases where processing should be divided into tasks from the viewpoint of task scheduling or preemption in the OS.
- Dividing Tasks for Parallel Processing
When some processes need to be executed in parallel (doing a process while doing another) within a specified period, execution should be switched between processes with wait conditions or at specified intervals and each process will continue intermittently. In this case, processes that need to be executed in parallel should be divided into separate tasks. Processes that are never executed in parallel need not be divided into tasks; in C language, such processes can be implemented through functions. It is important to consider which processes should work in parallel when dividing tasks. The fact that all processes within a single task have the same priority will also serve as a guideline for task division. - Dividing Tasks for Priority-Based Processing
As shown in the earlier description of scheduling, tasks having the same priority are switched in the FCFS manner and a necessary task might not be executed first. When a task that needs to be preempted has the same priority as the current task being executed, the target task is not executed until the current task enters a waiting state. In other words, the processing to be preempted should be created as a separate task and a high priority level should be assigned to it. When different priority levels need to be assigned to multiple processes, they should be divided into separate tasks. In general, the highest priority is assigned to urgent processing needed to handle system failures and processing that will affect real-time operation if it is not executed in high speed; a low priority is assigned to processing that only needs to be executed during an unoccupied period, such as system log maintenance processing. The lowest-priority tasks are called idle tasks because they can be executed while no other task is being executed. Loop processing that performs no operation may be created for idling in some cases.
Notes on Priority-Based Processing
When assigning priority to tasks, note that execution of a low-priority task may be suspended even while it is executing very important processing, and lower-priority tasks are never executed while a higher-priority task is being executed.
(6) OS Functions
The OS provides many functions as well as the scheduling functions. μITRON Version 4 has the following functions.
- a. Task Management: Reference and control of task states
Example: Activating or terminating a task - b. Task Dependent Synchronization: Control of task states to synchronize tasks
Example: Waking up a task or waiting for task wakeup - c. Synchronization and Communication: Waiting and communication mechanisms
Semaphore: Waiting mechanism between tasks, mainly used to wait for shared resources
Event Flag: Waiting mechanism between tasks, used to notify the end of processing, etc.
Mailbox: Data transfer and waiting mechanism between tasks, used to send and receive messages - d. Memory Pool: Allocation and release of memory required by tasks
In addition to the above, the OS has data queue, message buffer, mutex, rendezvous, task exception handling, time management, interrupt management, system state management, service call management, and system configuration management functions. To implement these functions in systems, specific service calls are provided. A total of 165 service calls are provided in μITRON Version 4.
(7) Disadvantages and Performance of an Embedded OS
- a. The OS occupies the memory area
As the OS is embedded in memory as part of the execution program, a necessary amount of memory area for the OS should be prepared. The necessary memory size depends on the numbers of OS functions to be used and the task and wait reason queues to be prepared. - b. Internal processing in the OS takes time
A certain amount of time is needed after a task issues a service call until the OS processes it and switches a task as necessary. The required function processing time depends on the requested service. Complex processing such as inter-task communication through a mailbox takes more time. A certain amount of time is also needed for task switching after scheduler processing until dispatching, and this is called the task switching time. - c. The OS disables interrupts
While the OS is executing internal processing, no other program should be activated through an interrupt signal in some cases. The OS issues an instruction to the CPU to disable interrupts for a certain period to avoid this problem. This period is called the interrupt-disabled period specified by the OS.
These common loads on the entire system generated through OS intervention are called the OS overhead. The OS performance is improved by reducing the overhead values. These values are shown in the OS catalogues to indicate the OS performance.